Automatic Speech Recognition: How ASR Works in 2026
How automatic speech recognition works in 2026: from Hidden Markov Models to CTC, RNN-T, and transformer architectures like Whisper and Parakeet.
Automatic speech recognition (ASR) is the technology that converts spoken audio into written text. Every voice assistant, dictation app, and transcription service runs some form of it underneath — a neural network trained to map audio waveforms to text tokens.
The technology has moved faster than most people realize. In 2012, the dominant approach combined hand-crafted acoustic models with statistical language models. By 2022, a single transformer trained on 680,000 hours of audio — OpenAI's Whisper — matched those systems on most benchmarks and ran on consumer hardware. By May 2025, NVIDIA's Parakeet TDT 0.6B v2 achieved 1.69% word error rate on the standard LibriSpeech benchmark, well below the estimated 5% human baseline for clean read speech, while processing audio at thousands of times real-time speed.
This is a guide to how ASR works: the pipeline that converts audio to text, the architectures behind current models, and what those technical differences mean if you're choosing a speech recognition app for Mac.
Here's how the major ASR architectures and models compare at a glance:
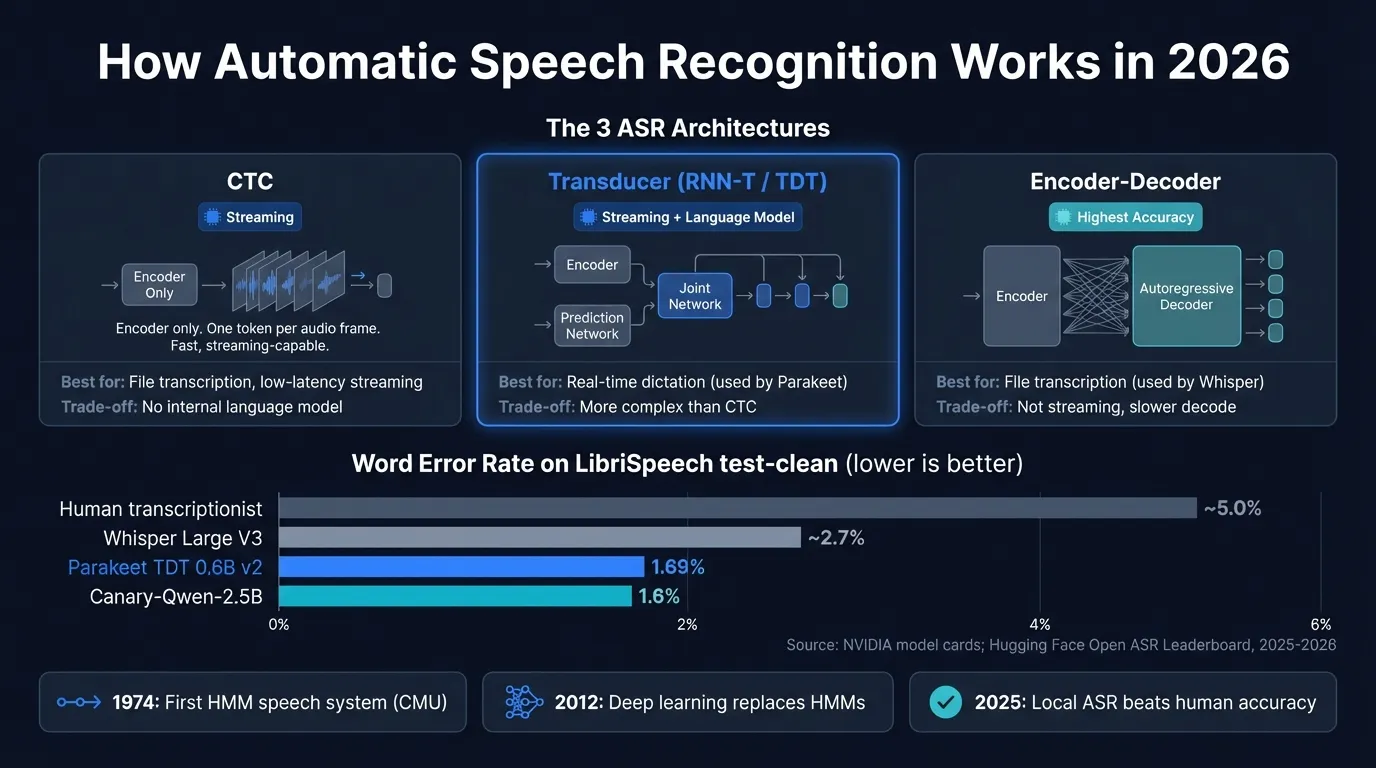
How ASR turns audio into text#
Modern end-to-end ASR systems take raw audio and output text in a single pass. Three steps happen under the hood.
Feature extraction. Raw audio is sampled at 16,000 Hz or higher and transformed into a mel spectrogram, a two-dimensional representation mapping time against frequency, weighted toward the ranges the human ear is most sensitive to. This discards pitch variation and absolute volume while preserving the phonetic content that distinguishes words. Most modern models process 80-channel mel spectrograms over 25ms windows, stepping forward in 10ms increments.
Acoustic encoding. A neural network encoder reads the mel spectrogram and produces high-dimensional representations of each audio frame. Modern encoders are typically Conformer networks, a hybrid of convolutional and self-attention layers. The convolutional layers capture local phonetic patterns; the self-attention layers capture longer-range dependencies like co-articulation and prosody. The encoder is where most of the "hearing" happens: it maps acoustic signals to linguistic representations.
Text decoding. The decoder takes the encoder's output and produces text tokens. This is where the three main ASR architecture families diverge.
Three generations of ASR#
Modern ASR descends from three distinct eras, each making a specific set of assumptions about the problem.
Hidden Markov Models (1974 to 2011)#
James Baker's DRAGON system at Carnegie Mellon University in 1974 was the first to apply Hidden Markov Models to speech recognition. The approach treats speech as a sequence of acoustic states (phones) that transition probabilistically over time. Separate Gaussian Mixture Models estimated how likely each observed audio frame was to belong to each state.
HMM-GMM systems dominated for 35 years because they worked. By the 1990s, IBM ViaVoice enabled continuous speech dictation on consumer PCs. But they required careful engineering: custom phonetic dictionaries, pronunciation lexicons, and separate language models trained on text corpora. The components were loosely coupled. Improving one didn't automatically improve the others.
The HMM's Markov assumption — that the current state depends only on the previous state, not the full history — was also a simplification the model could only partially compensate for. Human speech isn't cleanly segmentable into independent phone-sized chunks.
DNN-HMM hybrids (2012 to 2016)#
The inflection point was 2012. Hinton et al. published "Deep Neural Networks for Acoustic Modeling in Speech Recognition," demonstrating that replacing the GMM component with a deep neural network cut word error rates sharply on standard benchmarks. The DNN learned acoustic-phonetic representations directly from data, without manual feature engineering. Every major speech lab — Google, Microsoft, IBM, Baidu — adopted DNN-HMMs within two years.
The hybrid kept the HMM's temporal framework while replacing its weakest part. But it was still a pipeline: separate acoustic models, pronunciation dictionaries, and n-gram language models, each trained on different data with different objectives. Errors in one component cascaded into others.
End-to-end neural ASR (2016 to present)#
The key insight of end-to-end ASR: train a single model to map audio directly to text, jointly optimizing every component. Three architectures emerged from this approach.
The three modern ASR architectures#
CTC (Connectionist Temporal Classification)#
Graves et al. introduced CTC in 2006; it became widely adopted in end-to-end systems around 2016. CTC adds a single linear projection and softmax to an encoder, predicting one output token per input frame plus a special blank token. The CTC loss function marginalizes over all possible alignments between input frames and output tokens during training, removing the need for frame-level labels. At inference time, the model collapses repeated predictions and blanks to recover the output sequence.
The result: simple architecture, fast inference, naturally streaming-capable. Each output token is predicted independently given the encoder output, which limits implicit language modeling. CTC models benefit significantly from an external language model at decode time, and they're common in production systems where speed is critical.
RNN-T / Transducer#
Graves introduced the transducer in 2012. It adds a prediction network (a recurrent language model over previously emitted tokens) alongside the acoustic encoder. A joint network merges both outputs to predict the next token. This gives the model an internal language model that conditions each prediction on the full emission history.
The transducer is naturally streaming: it emits tokens as audio arrives, without waiting for a full sentence to end. This makes it the dominant architecture for production real-time ASR. Google's on-device speech recognition runs transducer models. NVIDIA's Parakeet uses a variant called TDT (Token-and-Duration Transducer), which predicts both token identity and token duration simultaneously. The duration prediction reduces autoregressive steps and speeds up inference.
Attention encoder-decoder#
Chorowski et al. introduced attention-based ASR in 2015; Whisper is the most widely known implementation. The architecture adapts the machine translation transformer to audio. A Transformer encoder processes the full audio input; a Transformer decoder generates output tokens autoregressively, using cross-attention over encoder outputs at each step.
Because the decoder attends to any part of the audio representation when generating each word, it learns strong implicit language modeling and handles long-range dependencies well. This generally produces the highest accuracy on offline tasks. The trade-off: autoregressive decoding is sequential (each token requires a forward pass), and the model must see the full audio chunk before it starts decoding. It's not streaming in the same way a transducer is.
OpenAI released Whisper in September 2022, trained on 680,000 hours of multilingual audio covering 99 languages. Its zero-shot transcription — no fine-tuning required for new languages or domains — was a significant practical advance over the pipeline systems it replaced.
Continue reading
AI Transcription That Stays on Your Mac
Run Whisper and Parakeet locally with a native Mac app. No Python setup, no command line.
Accuracy in 2026: current benchmarks#
Word error rate (WER) is the standard accuracy metric: the percentage of words in the output that differ from the reference transcript, accounting for insertions, deletions, and substitutions. Lower is better. LibriSpeech test-clean, a dataset of studio-quality audiobook readings, is the benchmark most widely cited for English ASR.
| Model | Architecture | LibriSpeech test-clean WER | Training data |
|---|---|---|---|
| NVIDIA Canary-Qwen-2.5B | Conformer + LLM decoder | 1.6% | — |
| NVIDIA Parakeet TDT 0.6B v2 | Conformer + TDT | 1.69% | ~120,000 hours |
| Whisper Large V3 | Transformer enc-decoder | ~2.7% | 680,000 hours |
| Whisper Large V3 Turbo | Transformer enc-decoder | ~2.7% | 680,000 hours |
| Human transcriptionist (read speech) | — | ~5% | — |
Sources: NVIDIA Hugging Face model cards; OpenAI Whisper paper (arXiv:2212.04356, 2022); Hugging Face Open ASR Leaderboard (accessed March 2026).
Two things stand out. First, the best open-source models have surpassed human-level accuracy on clean read speech by a wide margin: Parakeet TDT 0.6B v2 at 1.69% WER versus the ~5% human baseline. Second, the top of the leaderboard is now occupied by hybrid models (Canary-Qwen-2.5B, IBM Granite-Speech-3.3-8B) that pair a Conformer acoustic encoder with an LLM decoder. Encoder-decoder models like Whisper are no longer the accuracy leaders.
These benchmarks measure clean, standard English. For difficult audio — heavy accents, background noise, medical or legal terminology — the gap between models matters more, and some cloud services using larger models maintain an edge in those conditions. The LibriSpeech test-other set (more challenging recording conditions) shows higher WER across all models.
Speed: real-time factor for live dictation#
For file transcription, accuracy is the primary metric. For live voice typing, latency determines whether the experience feels natural.
Real-time factor (RTFx) measures how many seconds of audio a model processes per second of compute time. An RTFx of 1.0 means the model keeps up with speech in real time; 100x means it processes an hour of audio in 36 seconds.
| Model | Architecture | Real-time factor (GPU) | Streaming |
|---|---|---|---|
| NVIDIA Parakeet CTC 1.1B | CTC | ~2,793x | Yes |
| NVIDIA Parakeet TDT 0.6B v2 | TDT | ~3,000x+ | Yes |
| Whisper Large V3 Turbo | Enc-decoder | ~60x (Apple Silicon) | No |
| Whisper Large V3 | Enc-decoder | ~30x (Apple Silicon) | No |
Sources: Hugging Face Open ASR Leaderboard; NVIDIA model cards (2025).
The speed difference between transducer and encoder-decoder models isn't just about processing time. Transducer and CTC models emit tokens as audio arrives, so text appears while you're still speaking. Encoder-decoder models process audio in fixed-length chunks and decode after each chunk finishes. In practice on Apple Silicon, Parakeet TDT produces text within about 50ms of you finishing a phrase. Whisper Large V3 takes 1 to 2 seconds per segment. Both are usable for dictation; the difference is noticeable when you're dictating quickly.
For file transcription — podcasts, recordings, long-form interviews — the streaming distinction doesn't matter. Encoder-decoder models process the file faster than real-time regardless; the extra latency per segment only affects live use.
Why ASR now runs locally on a Mac#
Consumer hardware running state-of-the-art ASR models would have been implausible in 2019. Three developments made it practical.
Apple Silicon's Neural Engine. M-series chips include dedicated neural network accelerators with sustained throughput far exceeding CPU alone. Whisper Large V3 — 1.55 billion parameters — runs at real-time speed or faster on an M2 MacBook Pro. The same chip processing your email also runs a model trained on more audio data than existed in the world when HMM-GMM systems were the state of the art.
Efficient quantization. ML frameworks like whisper.cpp, mlx-whisper, and NVIDIA NeMo run models at 4-bit or 8-bit precision rather than 32-bit floating point. This cuts memory requirements by 4 to 8x with minimal accuracy loss. A model requiring 12 GB at full precision runs in about 3 GB. On Apple Silicon's unified memory architecture, that's often the difference between fits and doesn't fit.
Smaller, faster model architectures. Parakeet TDT 0.6B v2 has 600 million parameters and achieves 1.69% WER while processing audio at thousands of times real-time speed. A model that's simultaneously more accurate than human transcriptionists on clean speech and orders of magnitude faster than real-time is a fundamentally different category of tool than what was available five years ago.
The combined result: a dictation app on a Mac can transcribe speech more accurately than a professional typist, with under 50ms latency, without sending audio to a server.
How the architectures map to use cases#
Different ASR architectures suit different applications.
Real-time system-wide dictation (typing by voice into any app): Transducer or CTC models, for streaming output and low latency. Parakeet TDT is the current state of the art for English. Whisper-based dictation apps add 1 to 2 seconds of delay per segment, which is workable but noticeable.
File transcription (meetings, podcasts, interviews): Encoder-decoder models like Whisper have an accuracy advantage because they process the full audio context. Latency doesn't matter when you're transcribing offline. MacWhisper, the Whisper CLI, and similar tools use this approach.
Multilingual transcription: Whisper was trained on 680,000 hours covering 99 languages. Parakeet TDT 0.6B v2 is English-only. For French, German, Japanese, or other languages, Whisper Large V3 is the appropriate model.
Regulated environments (healthcare, legal, finance): Any scenario where audio leaving your device creates compliance complexity. Local ASR removes the data transmission issue structurally. Both Whisper and Parakeet run entirely on-device.
Difficult audio (heavy background noise, strong accents, domain-specific terminology): GPT-4o-transcribe and Canary-Qwen-2.5B handle these conditions better than Whisper. Neither runs locally on current consumer hardware — that's the trade-off.
ASR and AI post-processing#
Pure ASR converts audio to text as spoken, including filler words, false starts, and informal grammar. For most dictation use cases, the raw transcript is close enough to useful. For structured output — a formal email, a code comment, meeting notes — an LLM post-processing step cleans up the transcript without changing the meaning.
This two-stage pipeline can run locally. An ASR model produces the transcript; a local LLM (Qwen 2.5 3B, Llama 3.2, or similar) applies any requested transformation. The ASR step is fast: Parakeet produces the transcript in milliseconds. The LLM step adds 1 to 3 seconds depending on the model and prompt length. The combination — fast local ASR followed by optional local LLM cleanup — is what Hearsy implements: Parakeet or Whisper for transcription, with an optional post-processing stage via local or cloud LLM.
Where ASR is heading#
The pattern from 2024 and 2025 is clear: models pairing a Conformer acoustic encoder with an LLM decoder (Canary-Qwen, IBM Granite-Speech) outperform both pure audio models and standalone language models on the same transcription task. The acoustic encoder handles speech-specific processing; the LLM decoder handles language modeling. Combining both in a single end-to-end system produces accuracy levels that weren't achievable five years ago.
The hardware constraint on running these larger hybrid models locally — they require more GPU memory than current M-series chips comfortably provide — will likely ease over the next few hardware generations. The practical implication for Mac users: the local state of the art for English dictation already beats professional transcriptionists on clean speech. What improves over the next few years is accuracy on difficult audio and broader multilingual model support on consumer hardware.
Choosing an ASR app for Mac#
| Use case | Recommended approach |
|---|---|
| Real-time English dictation, low latency | Local app with Parakeet engine (Hearsy, Spokenly) |
| Multilingual dictation (99 languages) | Local app with Whisper mode (Hearsy, SuperWhisper) |
| Audio file transcription | MacWhisper |
| Maximum accuracy on difficult audio | Cloud API (GPT-4o-transcribe) |
| Privacy-sensitive content | Any fully local app |
For a detailed comparison of Whisper and Parakeet at the model level, see Whisper vs Parakeet. For the accuracy and privacy trade-offs between local and cloud processing, see AI transcription: local vs cloud. For Whisper model variants, see Whisper Large V3 vs V3 Turbo. For a guide to setting up local speech recognition on Mac, see voice recognition setup for Mac.
Frequently asked questions#
What is automatic speech recognition?#
Automatic speech recognition (ASR) is the technology that converts spoken audio into written text using machine learning. Modern ASR systems are end-to-end neural networks trained on hundreds of thousands of hours of labeled audio. They map raw audio waveforms — represented as mel spectrograms — to text tokens in a single learned pipeline, without separate hand-crafted acoustic models or pronunciation dictionaries. The three dominant architectures are CTC, transducer (RNN-T), and attention encoder-decoder.
What is word error rate and how is it measured?#
Word error rate (WER) is the standard metric for ASR accuracy. It measures the percentage of words in the output that differ from the reference transcript, counting insertions (extra words), deletions (missing words), and substitutions (wrong words). A WER of 2% means 2 out of every 100 words differ from the reference. Human transcriptionists achieve approximately 5% WER on clean read speech. State-of-the-art models like NVIDIA Parakeet TDT 0.6B v2 achieve 1.69% WER on the LibriSpeech test-clean benchmark (NVIDIA, 2025).
How does Whisper work?#
Whisper is an encoder-decoder Transformer trained on 680,000 hours of multilingual audio (OpenAI, September 2022). It converts audio to an 80-channel mel spectrogram, encodes it with a Transformer encoder, and decodes text autoregressively with a Transformer decoder using cross-attention over encoder outputs. This architecture achieves high accuracy because the decoder can attend to any part of the full audio representation when generating each word. The trade-off: it processes audio in fixed-length chunks and cannot stream text token-by-token as you speak.
What is the difference between CTC, RNN-T, and attention encoder-decoder ASR?#
CTC uses an encoder only, predicting one token per input frame independently — simple architecture, fast streaming, but limited internal language modeling. RNN-T (transducer) adds a recurrent prediction network that conditions each output on previously emitted tokens, giving the model an internal language model while remaining naturally streaming-capable. It's the dominant architecture for production real-time ASR. Attention encoder-decoder models (Whisper) use a full Transformer decoder with cross-attention, achieving the highest accuracy on offline tasks at the cost of sequential decoding and the need to buffer a full audio chunk before starting output.
What ASR models run locally on Apple Silicon in 2026?#
Whisper Large V3 (1.55B parameters, approximately 3.1 GB RAM) runs at real-time speed or faster on M2 and later chips using whisper.cpp or mlx-whisper. NVIDIA Parakeet TDT 0.6B v2 (600M parameters) runs on Apple Silicon using the NVIDIA NeMo framework or community ports, achieving 1.69% WER on LibriSpeech test-clean with thousands-of-times real-time processing speed. Both models run entirely on-device — no internet connection required, no audio transmitted to external servers.
Ready to Try Voice Dictation?
Hearsy is free to download. No signup, no credit card. Just install and start dictating.
Download Hearsy for MacmacOS 14+ · Apple Silicon · Free tier available
Related Articles
What Is OpenAI Whisper? A Complete Guide to Local AI Transcription
14 min read
Whisper vs Parakeet: Speed, Accuracy, and Language Support
10 min read
Whisper Large V3 vs V3 Turbo: Speed, Accuracy, Memory
10 min read
How to Run Whisper Locally on Mac (Without the Command Line)
8 min read
How to Convert Audio to Text on Mac: 5 Methods Compared
14 min read