Where Does Your Voice Data Go? What Cloud Dictation Apps Don't Tell You
When you use cloud-based dictation, your voice travels to servers — where it's stored, analyzed, and sometimes reviewed by humans. Here's what actually happens, and how local processing changes the equation.
In 2019, a whistleblower contacted The Guardian with a straightforward claim: Apple contractors were listening to Siri recordings. Not just a few — up to 1,000 recordings per reviewer per day, including confidential medical details, drug deals, and intimate conversations. Users had no idea this was happening.
Apple wasn't unusual. The same year, a contractor leaked over 1,000 Google Assistant recordings to a Belgian news outlet, VRT. The Hamburg data protection authority ordered Google to stop human review entirely. Amazon faced similar scrutiny — and in 2023, paid over $30 million to settle FTC charges related to Alexa voice data retention practices, including keeping children's recordings even after parents requested deletion.
These weren't isolated failures. They were a predictable outcome of how cloud voice services work: your audio goes to their servers, where it can be stored, reviewed, and used for purposes that serve the company's interests.
Voice data privacy refers to the controls — technical and policy-based — that govern what happens to your voice recordings after you speak. For cloud services, those controls are policies you have to trust. For local apps, they're structural: audio that never leaves your device can't be leaked, stored, or reviewed.
Here's what happens to your voice data with cloud vs local dictation:
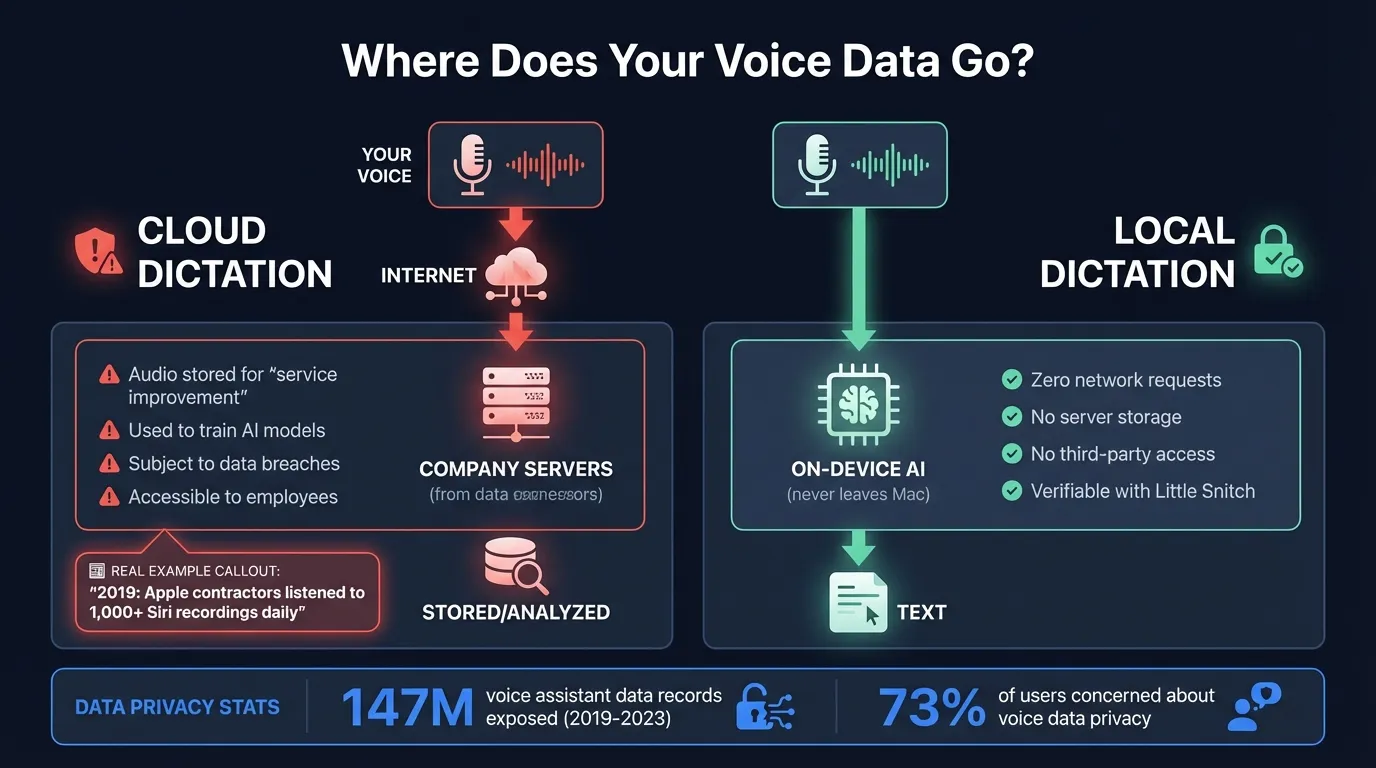
What happens when you use cloud dictation#
When you press the microphone button in a cloud dictation app, here's what happens technically:
Your microphone captures audio. The app compresses it and sends it over your internet connection to the company's servers. The server runs the speech recognition model — the same Whisper-based or proprietary model that local apps could run on your device — and returns a text transcription. That audio and text may then be stored, depending on the service's retention policy.
The part most users don't see: that audio exists on a server somewhere. What happens next depends entirely on the service's terms of service, which change over time and which most users never read.
Common things that happen to stored voice data:
Quality review by humans. This is what the 2019 incidents exposed. Companies hire contractors to listen to recordings and correct errors, which improves model accuracy. The audio samples passed to reviewers are typically stripped of account identifiers, but as the Google incident showed, they still contain enough context to identify individuals.
Model training. Most cloud services that retain audio use it to improve their speech recognition models. This is the business rationale for retaining audio at all — better training data means better models. Wispr Flow's privacy policy states explicitly that without enabling Privacy Mode, "Dictation Data may be used to evaluate, train and improve Flow's features and AI models."
Third-party sharing. Cloud apps typically use third-party infrastructure — cloud providers, AI model APIs, analytics platforms. Your audio may transit through multiple companies before becoming text.
Policy changes. In March 2025, Amazon removed the "Do Not Send Voice Recordings" option for Echo users, making it impossible to prevent voice recordings from going to Amazon's cloud — a setting that had previously existed. Terms of service can change; local processing cannot be revoked.
What "private" actually means on a policy#
Several cloud apps now market privacy features. Understanding what these actually do matters.
Zero data retention means the service deletes audio and transcripts immediately after generating the transcription — nothing is stored. Wispr Flow's Privacy Mode works this way. This is meaningfully better than standard retention, but audio still reaches their servers during processing.
Encryption in transit and at rest is standard practice among reputable cloud services, including Wispr Flow. This protects against interception during transmission and against storage breaches. It does not prevent the company itself from accessing your data.
No human review means the company doesn't employ contractors to listen to recordings. Some services offer this as a setting. It addresses one risk — humans listening — but not others.
Business Associate Agreements (BAAs) for HIPAA are contracts a cloud service can sign, promising to handle protected health information according to HIPAA requirements. This creates legal accountability but doesn't change the technical reality: audio leaves your device.
All of these are policy commitments. They can be honored, violated, or changed. The privacy protection depends on the company continuing to enforce it.
Your Voice, Your Mac, Your Data
Hearsy processes everything on-device. Your voice never leaves your Mac — not even for a millisecond.
What local processing actually guarantees#
Local dictation software processes audio entirely on your device. The speech recognition model runs in RAM — on your CPU, GPU, or Neural Engine. Audio is captured, converted to text, and the audio is discarded. Nothing is transmitted.
This isn't a privacy policy. It's a technical fact you can verify.
A network monitor like Little Snitch shows every outbound connection your Mac makes. When using a properly built local dictation app, you will see zero network requests during transcription. The audio doesn't exist on any server because it was never sent to one.
The implications:
No breach exposure. Data that was never transmitted cannot be stolen from a server. Voice data breaches require voice data to exist somewhere they can be breached.
No human review. There are no contractors to listen to your recordings, because your recordings never reach the company.
No model training on your voice. Local apps don't have an incentive to retain your audio — they're not building centralized models. Each user's audio stays on their device.
No policy dependency. A cloud service can add a privacy feature, or remove one. Local processing doesn't have this risk. The architecture doesn't change with the terms of service.
Regulatory simplification. For professionals in healthcare, legal, or finance — where voice data may constitute protected health information or privileged communications — local processing dramatically simplifies compliance. Data that stays on-device doesn't trigger most requirements around transmission, storage, and third-party access.
Who needs to care#
The default answer for many users is: "I'm not saying anything secret." Fair. If you're dictating grocery lists and quick messages, the practical risk from cloud processing is low.
But consider what most people actually dictate over time:
Medical information. Dictating symptoms to yourself, notes from a doctor's appointment, insurance details. Under HIPAA, voice recordings containing patient information are protected health information. Cloud services require Business Associate Agreements to handle PHI; most consumer apps don't have these in place.
Legal discussions. Notes from meetings with attorneys, legal strategy, case details. Attorney-client privilege typically extends to the attorney's communications, but the cloud service you used to dictate your notes isn't your attorney.
Business confidential information. Competitive strategy, financial projections, personnel matters. Dictating these into a cloud service means that content exists on a third party's infrastructure.
Relationship conversations. Personal messages, sensitive communications. The 2019 incidents exposed that Siri recordings included couples' arguments and intimate moments — triggered by accidental activation, not intentional use.
The pattern: over any significant period, most people dictate something they'd prefer to keep private. Cloud services record and store everything by default.
The practical comparison#
| Factor | Cloud Dictation | Local Dictation |
|---|---|---|
| Audio stored on external servers | Yes | No |
| Human review possible | Yes (varies by policy) | No |
| Used for model training | Yes (unless opted out) | No |
| Network required | Yes | No |
| Breach exposure | Yes | No |
| Privacy depends on | Company's policies | Technical architecture |
| Policy change risk | Yes | No |
| Regulatory compliance burden | Higher | Lower |
What local dictation looks like in practice#
On a Mac with Apple Silicon, local speech recognition is fast. NVIDIA Parakeet TDT 0.6B v2 — the model Hearsy uses for English — achieves under 50ms latency and 1.69% word error rate on the LibriSpeech clean benchmark (NVIDIA, 2025). OpenAI Whisper Large V3 runs at real-time speed on M2 and later chips, covering 99 languages.
The experience: press a hotkey, speak, text appears at your cursor. No network request. No waiting for a cloud round-trip. Works on a plane or in a building with no Wi-Fi.
The difference from cloud isn't a trade-off anymore. For clear speech in a quiet environment — the context of most real dictation — local models match cloud accuracy and respond faster, because there's no network latency.
One thing worth checking#
If you currently use a cloud dictation app, look at its privacy settings. Find the data retention policy. Check whether there's a zero-retention or privacy mode and whether it's enabled by default or requires opting in.
Wispr Flow's Privacy Mode, for example, offers zero data retention — but it's not the default setting. Most users who care about privacy don't know it exists.
For persistent privacy — where the protection doesn't depend on remembering to check a settings toggle or on a company maintaining its current policies — local processing is the answer. Your audio stays on your device because the architecture doesn't send it anywhere.
That's not a policy. It's a technical guarantee.
For a comparison of local dictation apps available on Mac, see the best dictation software for Mac guide. For how on-device AI speech models work technically, see the AI transcription local vs cloud breakdown. For HIPAA and GDPR implications of voice data, see the HIPAA and GDPR voice dictation guide.
Frequently asked questions#
What is private dictation software?#
Private dictation software processes your voice entirely on your device — no audio is transmitted to external servers. Apps like Hearsy, MacWhisper, and SuperWhisper on Mac run AI speech recognition models locally in RAM. When you dictate, audio is captured, converted to text, and discarded without ever leaving your device. Privacy is structural, not policy-based: there's nothing to leak because nothing is transmitted.
Do cloud dictation apps listen to my recordings?#
Historically, many have — for quality review purposes. In 2019, whistleblowers revealed that Apple, Google, and Amazon all employed contractors to listen to voice recordings from their respective assistants. Apple settled a class action lawsuit for $95 million related to this practice. Most cloud services now offer opt-out options for human review, but audio still reaches their servers regardless. Whether humans actually listen depends on the service's current policy, which can change.
Is Wispr Flow private?#
Wispr Flow offers a Privacy Mode that enables zero data retention: audio and transcripts are deleted immediately after processing, and data is not used for model training. Privacy Mode must be enabled in Settings → Data and Privacy. Without it, the standard plan retains audio and transcripts for 30 days and may use them to improve Wispr's AI models. The app itself is cloud-based — audio still reaches their servers in both modes. Privacy Mode controls what happens after it arrives.
How can I dictate privately on Mac?#
Use a local dictation app that runs speech recognition on-device. Hearsy uses NVIDIA Parakeet for English (under 50ms latency) or OpenAI Whisper for 99 languages — both run entirely in RAM on Apple Silicon. No audio is transmitted. You can verify this with a network monitor like Little Snitch, which will show zero outbound connections during transcription. MacWhisper and SuperWhisper are alternatives with the same local-processing approach.
Does using local dictation affect accuracy?#
Not meaningfully for most use cases. NVIDIA Parakeet TDT 0.6B v2 achieves 1.69% word error rate on the LibriSpeech clean benchmark (NVIDIA, 2025). OpenAI Whisper Large V3 achieves approximately 2.7% WER on the same benchmark. Cloud services have an accuracy edge specifically on difficult audio — heavy accents, background noise, specialized vocabulary. For standard dictation of clear speech, local models match or beat cloud performance while responding faster, because there's no network round-trip.
Ready to Try Voice Dictation?
Hearsy is free to download. No signup, no credit card. Just install and start dictating.
Download Hearsy for MacmacOS 14+ · Apple Silicon · Free tier available