Whisper Large V3 vs V3 Turbo: Speed, Accuracy, Memory
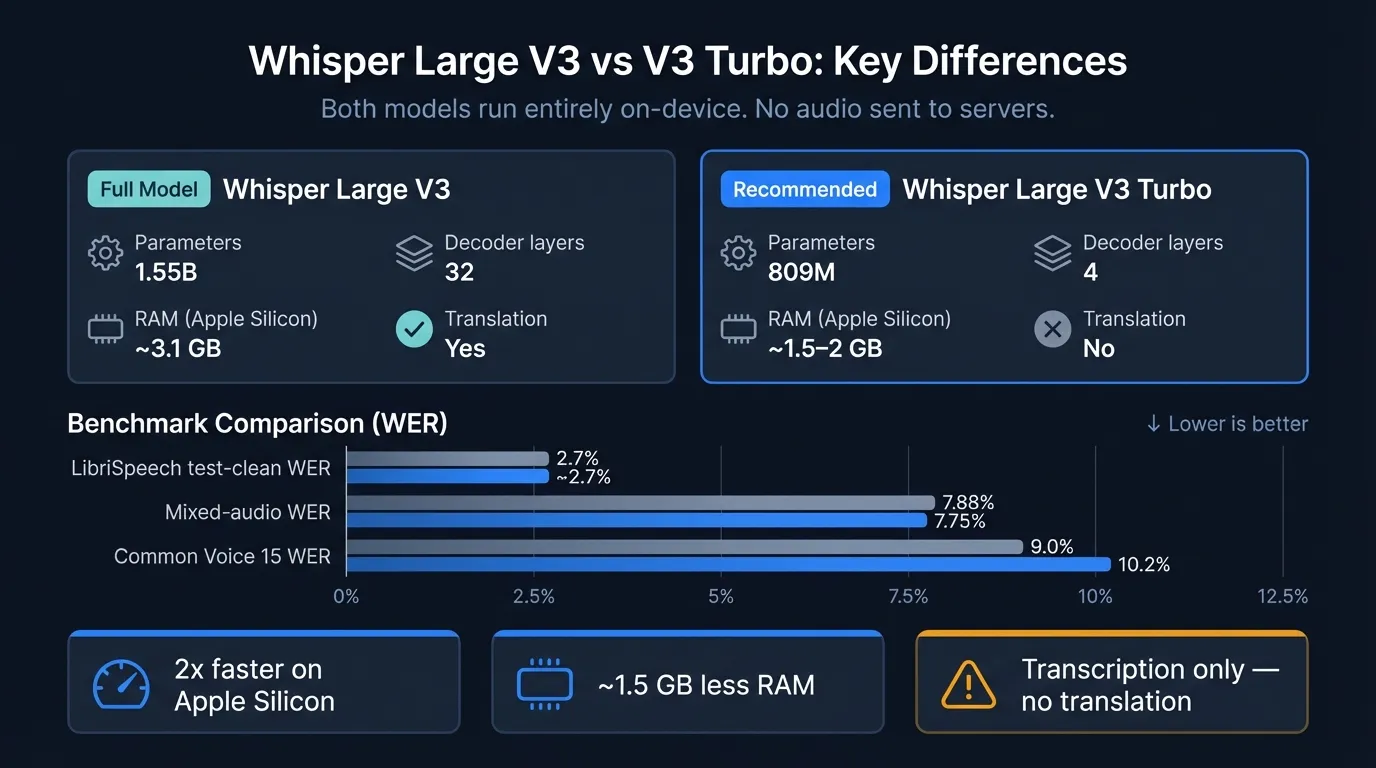
Whisper Large V3 Turbo cuts the decoder from 32 layers to 4 — half the RAM, 2x faster on Apple Silicon, and comparable accuracy on most benchmarks.
Whisper Large V3 Turbo uses 809 million parameters instead of 1.55 billion. The change is specific: OpenAI pruned the decoder from 32 layers to 4. The result is a model that transcribes audio roughly 8 times faster on GPU hardware, uses about half the RAM, and produces word error rates within 1–2% of Large V3 on most benchmarks.
The one meaningful trade-off: V3 Turbo cannot translate. The --task translate flag that converts non-English speech into English text does not work reliably with V3 Turbo. For transcription-only workflows, this doesn't matter. For anyone who uses Whisper as a translation engine, it matters a lot.
Here's how the two models compare across speed, accuracy, RAM, and capabilities:
What OpenAI changed in V3 Turbo#
Whisper Large V3 Turbo is not a new architecture — it's a pruned and fine-tuned version of Large V3. OpenAI released it in October 2024, drawing on prior work from the Distil-Whisper project, which showed that Whisper's decoder could be compressed aggressively with minimal accuracy loss.
The structural change is narrow but impactful. Both V3 and V3 Turbo use the same encoder: the 32-layer transformer that converts raw audio frames into acoustic representations. The decoder — the component that generates text tokens from those representations — drops from 32 layers to 4. OpenAI then fine-tuned the pruned model for two additional training epochs over the same multilingual data used for Large V3.
The encoder does most of the acoustic work. The decoder handles language modeling: given the acoustic representation, predict what text comes next. With only 4 layers, the decoder is faster but has less capacity to model complex linguistic context. This matters more for translation (which requires generative language modeling across languages) than for transcription (which mostly maps acoustic input to its spoken text). That's the reason translation is unreliable on V3 Turbo and not just a configuration quirk.
Whisper Large V3 accuracy benchmarks#
| Benchmark | Whisper Large V3 | Whisper Large V3 Turbo |
|---|---|---|
| LibriSpeech test-clean WER | ~2.7% | comparable |
| 10-hour mixed-audio WER | 7.88% | 7.75% |
| Common Voice 15 (multilingual) WER | 9.0% | 10.2% |
| Translation support | Yes | No |
Sources: OpenAI Whisper GitHub; Hugging Face whisper-large-v3-turbo; AssemblyAI benchmark testing (2024).
On clean speech — the LibriSpeech test-clean set, which uses studio-quality recordings — both models score around 2.7% WER. In that condition the difference is effectively zero.
The gap opens on Common Voice 15, a crowdsourced multilingual benchmark with varied accents and recording quality. V3 Turbo scores 10.2% versus V3's 9.0%. If your dictation is consistently clear English or standard European languages, you won't notice this difference. If you frequently work with accented speakers, non-standard recording setups, or non-European languages, V3 has a modest edge.
One detail worth noting: in the 10-hour mixed-audio test, V3 Turbo was marginally more accurate than V3 (7.75% vs 7.88%). This is within noise, but it illustrates that V3 Turbo is not a uniformly worse model — it's a different trade-off that favors speed and memory at minimal accuracy cost on most content.
Speed comparison on Apple Silicon#
OpenAI's own benchmarks show V3 Turbo running approximately 8x faster than Large V3 on server GPU hardware. On Apple Silicon the improvement is smaller: roughly 2x in practice.
| Model | Approx. real-time factor (Apple Silicon) | RAM usage |
|---|---|---|
| Whisper Large V3 | ~30x | ~3.1 GB |
| Whisper Large V3 Turbo | ~60x | ~1.5–2 GB |
| Whisper Large V2 | ~25x | ~2.9 GB |
These figures vary by chip generation (M1 through M4) and runtime implementation. The 2x ratio between Turbo and V3 on Apple Silicon is consistent across whisper.cpp, faster-whisper, and mlx-whisper benchmarks (GitHub/mac-whisper-speedtest benchmarks, 2024).
For real-time dictation, what this means practically: both V3 and V3 Turbo produce latency in the 1–2 second range per segment on Apple Silicon. Turbo lands toward the lower end of that range. Neither approaches the streaming latency you get from Parakeet TDT — the architectural difference between chunk-based encoder-decoder processing and streaming transducers matters far more for real-time latency than V3 versus Turbo. See Whisper vs Parakeet for that comparison.
For file transcription — podcasts, recordings, interviews — the 2x speed difference is meaningful. V3 Turbo transcribes a 30-minute audio file in roughly half the wall-clock time of Large V3.
Continue reading
AI Transcription That Stays on Your Mac
Run Whisper and Parakeet locally with a native Mac app. No Python setup, no command line.
Memory on 8 GB and 16 GB Macs#
The decoder reduction cuts RAM usage by roughly half. Whisper Large V3 needs about 3.1 GB of unified memory. V3 Turbo uses approximately 1.5–2 GB. The encoder is the larger component in both models, which is why the RAM gap (about 1.5 GB) is smaller than the parameter gap (about 740M parameters) would suggest.
| RAM config | Whisper Large V3 | Whisper Large V3 Turbo |
|---|---|---|
| 8 GB Mac | Runs, limited headroom | Comfortable |
| 16 GB Mac | Comfortable | Comfortable |
| 24 GB+ Mac | No constraint | No constraint |
On an 8 GB MacBook Air running a browser, Slack, and a few other apps, Large V3 leaves little margin — you may see memory pressure. V3 Turbo leaves a comfortable buffer. On 16 GB machines both run fine; on 24 GB and above there's no practical difference.
What about distil-Whisper?#
Distil-Whisper is a community-developed model family from Hugging Face, released before V3 Turbo, that took the same approach: reduce Whisper's decoder to 2 layers and distill from the large model's output. It achieves accuracy close to Large V3 with very fast inference.
V3 Turbo is OpenAI's official response. At 4 decoder layers versus distil-large's 2, V3 Turbo is slightly slower but more accurate — and it's fine-tuned rather than distilled, which means it was trained on the target task rather than on the original model's predictions. For macOS apps, V3 Turbo has broader runtime support; most frameworks that shipped distil-Whisper support now also support V3 Turbo natively.
Whisper Large V2 vs V3 vs V3 Turbo#
V3 Turbo lands roughly in line with Large V2 on English accuracy benchmarks. OpenAI's documentation notes this explicitly. The difference: V3 Turbo benefits from V3's improved multilingual training data, so for non-English languages it outperforms V2 despite similar English accuracy.
If you're running Large V2 today, switching to V3 Turbo gets you better multilingual performance and faster inference with no accuracy trade-off for English.
| Model | Parameters | Decoder layers | RAM | Translation |
|---|---|---|---|---|
| Whisper Large V2 | 1.54B | 32 | ~2.9 GB | Yes |
| Whisper Large V3 | 1.55B | 32 | ~3.1 GB | Yes |
| Whisper Large V3 Turbo | 809M | 4 | ~1.5–2 GB | No |
Which to use#
Use Whisper Large V3 if:
- You use the
--task translateflag to convert non-English speech to English text - You transcribe heavily accented audio, noisy recordings, or difficult multilingual content where V3's deeper decoder context helps
- You're on a 16 GB+ Mac and memory is not a concern
- You process significant amounts of non-European languages
Use Whisper Large V3 Turbo if:
- You're doing transcription only (no translation needed)
- You're on an 8 GB Mac and want more headroom
- You want faster file transcription throughput
- Your content is primarily English or standard European languages
- You're doing real-time dictation and want to reduce latency
For most dictation workflows on Mac, V3 Turbo is the right default. The accuracy difference is small on standard speech content, the RAM reduction is meaningful on 8 GB machines, and the speed improvement matters for real-time use.
How Hearsy handles Whisper model selection#
Hearsy ships Parakeet TDT as its default engine — faster and more accurate than any Whisper variant for English real-time dictation. Whisper Large V3 is available in Settings → Speech Engine for 99-language coverage, translation tasks, or specialized transcription where Whisper's characteristics work better.
Switching takes one click. There's no terminal, no Python environment, no model file management. The model loads once at startup and stays resident in memory for zero-latency subsequent dictations.
Summary#
Whisper Large V3 Turbo reduces the decoder from 32 layers to 4, cutting parameters from 1.55B to 809M. On Apple Silicon, this produces roughly 2x faster transcription and about 1.5 GB less RAM usage compared to Large V3.
Accuracy is comparable for standard speech content. The accuracy gap opens on difficult audio — heavily accented speakers, noisy recordings, complex multilingual content — where V3's deeper decoder context gives a small edge.
The firm constraint: V3 Turbo cannot translate. If you need non-English speech converted to English text, use Large V3.
For transcription-only workflows on Mac, V3 Turbo is the better choice. For everything else, the differences are real but narrow.
For a broader look at how Whisper compares to newer streaming models, see Whisper vs Parakeet. For how local Whisper stacks up against cloud transcription services, see AI transcription: local vs cloud. For a guide to running Whisper locally without the command line, see how to run Whisper locally on Mac.
Frequently asked questions#
What is Whisper Large V3 Turbo?#
Whisper Large V3 Turbo is a pruned and fine-tuned version of OpenAI's Whisper Large V3, released in October 2024. OpenAI reduced the decoder from 32 layers to 4 layers, cutting the parameter count from 1.55 billion to 809 million. The model was then fine-tuned for two epochs on the same multilingual transcription data used for Large V3. The result is approximately 8x faster inference on GPU hardware and 2x faster on Apple Silicon, with accuracy comparable to Large V3 on most transcription benchmarks. V3 Turbo does not support translation tasks.
Is Whisper Large V3 Turbo less accurate than Large V3?#
For standard dictation — clear speech, desktop microphone, English or European languages — the accuracy difference is not practically significant. On a 10-hour mixed-audio benchmark, V3 Turbo scored 7.75% WER versus V3's 7.88%. On Common Voice 15 (a harder multilingual benchmark), V3 Turbo scores 10.2% versus V3's 9.0%. The gap is real but narrow for typical use cases; it becomes more relevant with difficult audio or non-European languages.
How much faster is V3 Turbo than Large V3?#
OpenAI reports approximately 8x faster inference on server GPU hardware. On Apple Silicon (M1 through M4), the improvement is closer to 2x in real-world tests. The gap is smaller on Apple Silicon because the Neural Engine handles the encoder — the unchanged component — very efficiently, and that work dominates total inference time regardless of model variant.
Why can't Whisper Large V3 Turbo translate?#
V3 Turbo was fine-tuned exclusively on transcription tasks, not translation. Translation requires the decoder to generate output in a different language than the input, which demands more language modeling capacity than a 4-layer decoder reliably provides. OpenAI's documentation explicitly notes that V3 Turbo will return the original language even when --task translate is specified, producing incorrect results. Use Large V3 or another full multilingual Whisper model for translation.
What is distil-Whisper and how does it compare to V3 Turbo?#
Distil-Whisper is a community-developed compression of Whisper, created by Hugging Face before OpenAI released V3 Turbo. It uses 2 decoder layers versus V3 Turbo's 4, making it slightly faster but marginally less accurate. Distil-Whisper uses knowledge distillation (training on the original model's output), while V3 Turbo was fine-tuned directly on transcription data. For macOS applications, V3 Turbo has broader native runtime support.
Ready to Try Voice Dictation?
Hearsy is free to download. No signup, no credit card. Just install and start dictating.
Download Hearsy for MacmacOS 14+ · Apple Silicon · Free tier available
Related Articles
What Is OpenAI Whisper? A Complete Guide to Local AI Transcription
14 min read
Whisper vs Parakeet: Speed, Accuracy, and Language Support
10 min read
How to Run Whisper Locally on Mac (Without the Command Line)
8 min read
How to Convert Audio to Text on Mac: 5 Methods Compared
14 min read
Best Whisper Apps for Mac in 2026: 7 Apps Compared
17 min read